claude-devkit: Repeatable Workflows for AI Coding Agents
The gap between “AI can write code” and “AI can run a reliable development process” is the same gap that CI/CD closed for manual deployments 15 years ago: structure, gates, repeatability.
Most people using AI coding agents type a prompt, hope for the best, and fix whatever breaks. That works for small tasks. It does not work when you need a plan reviewed by three specialists before a single line of code gets written, or when four agents need to implement code in parallel without stepping on each other’s files.
I built claude-devkit to close that gap for Claude Code. Today it’s open source.
The problem
Claude Code supports “skills”: markdown files that define multi-step workflows. Type /dream add user authentication and Claude executes a 6-step planning process instead of immediately writing code. Type /ship plans/feature.md and it runs pre-flight checks, dispatches parallel coders, runs code review, executes tests, and gates the commit on passing QA.
Skills are powerful. They’re also just markdown files. There’s no validation, no testing infrastructure, no generators, no deployment tooling, and no architectural patterns to follow when building your own. Teams end up reinventing the same patterns.
claude-devkit is 6 production skills, 3 generators, 11 templates, and a validation framework. It treats AI agent workflows the way we treat application code: version-controlled, tested, and deployable.
Four skills, one lifecycle
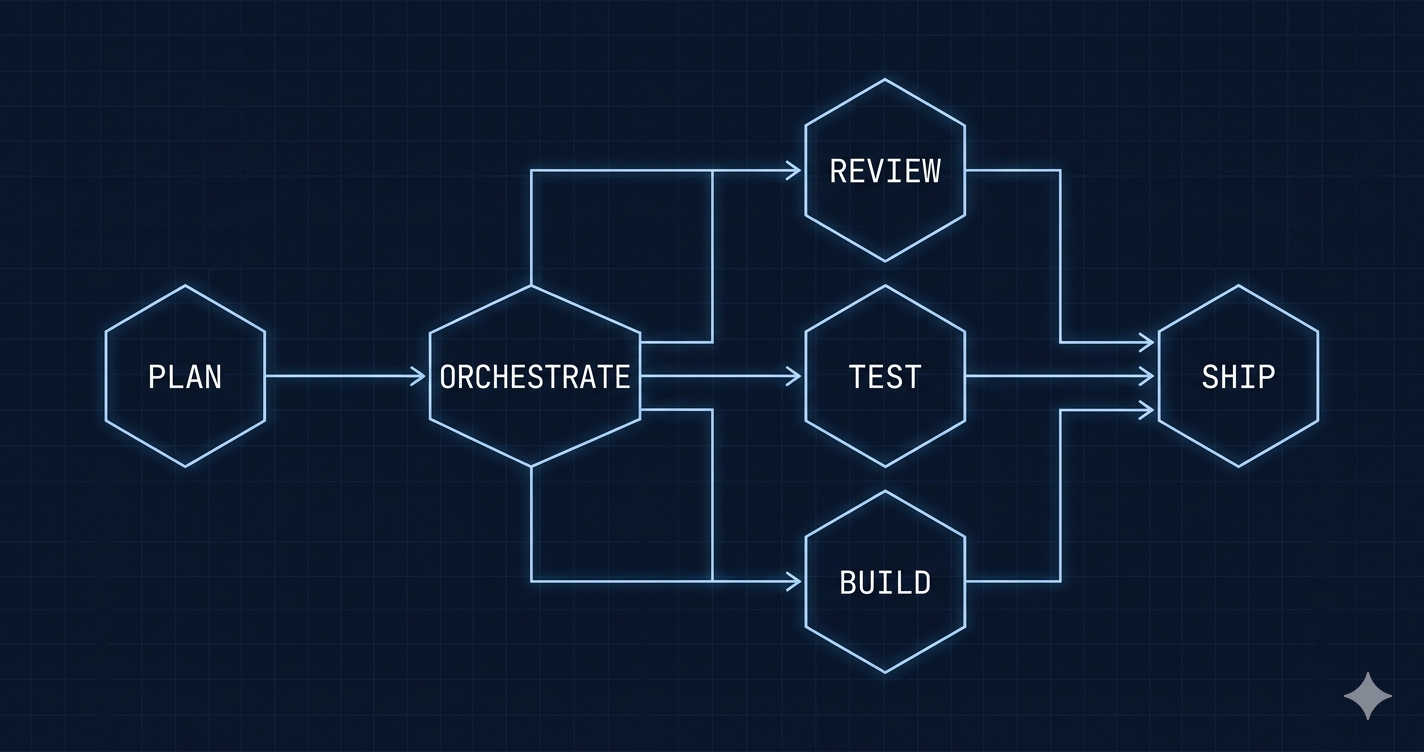
The core loop is 4 skills that cover a full feature lifecycle:
/dream add shopping cart # Plan with approval gates
/ship plans/add-shopping-cart.md # Implement with QA
/audit # Security + performance scan
/sync # Update documentationEach skill follows a different archetype.
/dream: the coordinator
/dream does not write a plan. It delegates to specialists and orchestrates their output.
- Context discovery. Reads
CLAUDE.md, recent plans, and archived plans. Assembles a context block so the architect has project history. - Architect drafts plan. Dispatches a senior-architect agent (project-specific if one exists, generic subagent if not).
- Parallel review. Three agents run simultaneously: a red team critic, a librarian checking consistency, and a feasibility reviewer.
- Revision loop. Max 2 iterations. The architect addresses review findings.
- Approval gate. APPROVED, NEEDS_WORK, or BLOCKED. Nothing moves forward without a verdict.
- Artifact commit. Auto-commits the plan, red team report, feasibility analysis, and librarian review.
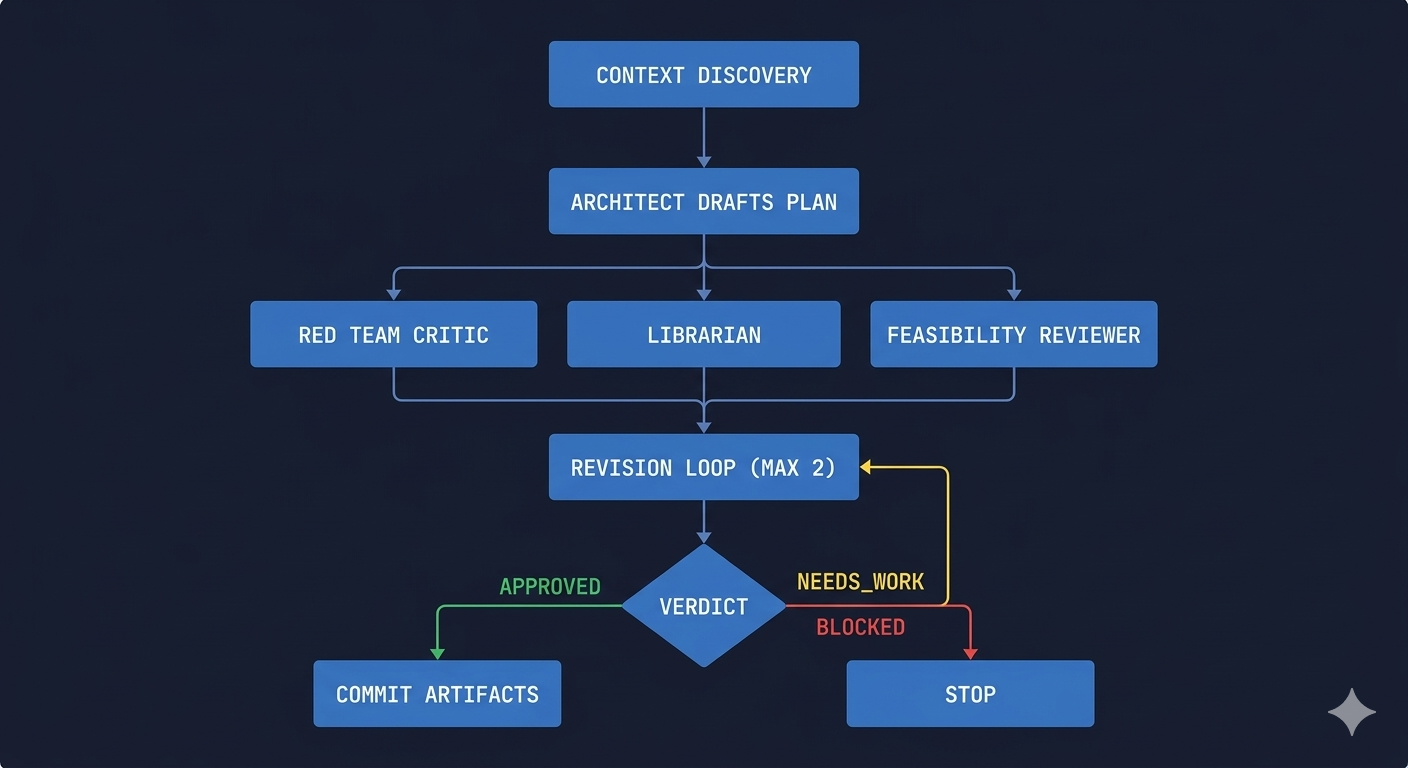
The output is 4 files in ./plans/. Not a chat response. Durable artifacts that /ship can consume.
/ship: the pipeline
/ship reads an approved plan and executes it. The interesting part is how it handles parallel implementation.
Worktree isolation. Every /ship run creates isolated git worktrees, one per work group defined in the plan. If your plan has 3 work groups (say, API endpoints, database migrations, and frontend components), each coder agent gets its own filesystem checkout. They physically cannot modify each other’s files.
After execution, /ship runs file boundary validation: it diffs each worktree and verifies that modified files are a subset of the scoped file list from the plan. Violations block the workflow. Only validated changes get merged back to the main tree.
This is not a convention or a “please don’t touch other files” instruction in a prompt. It’s a structural guarantee enforced by git.
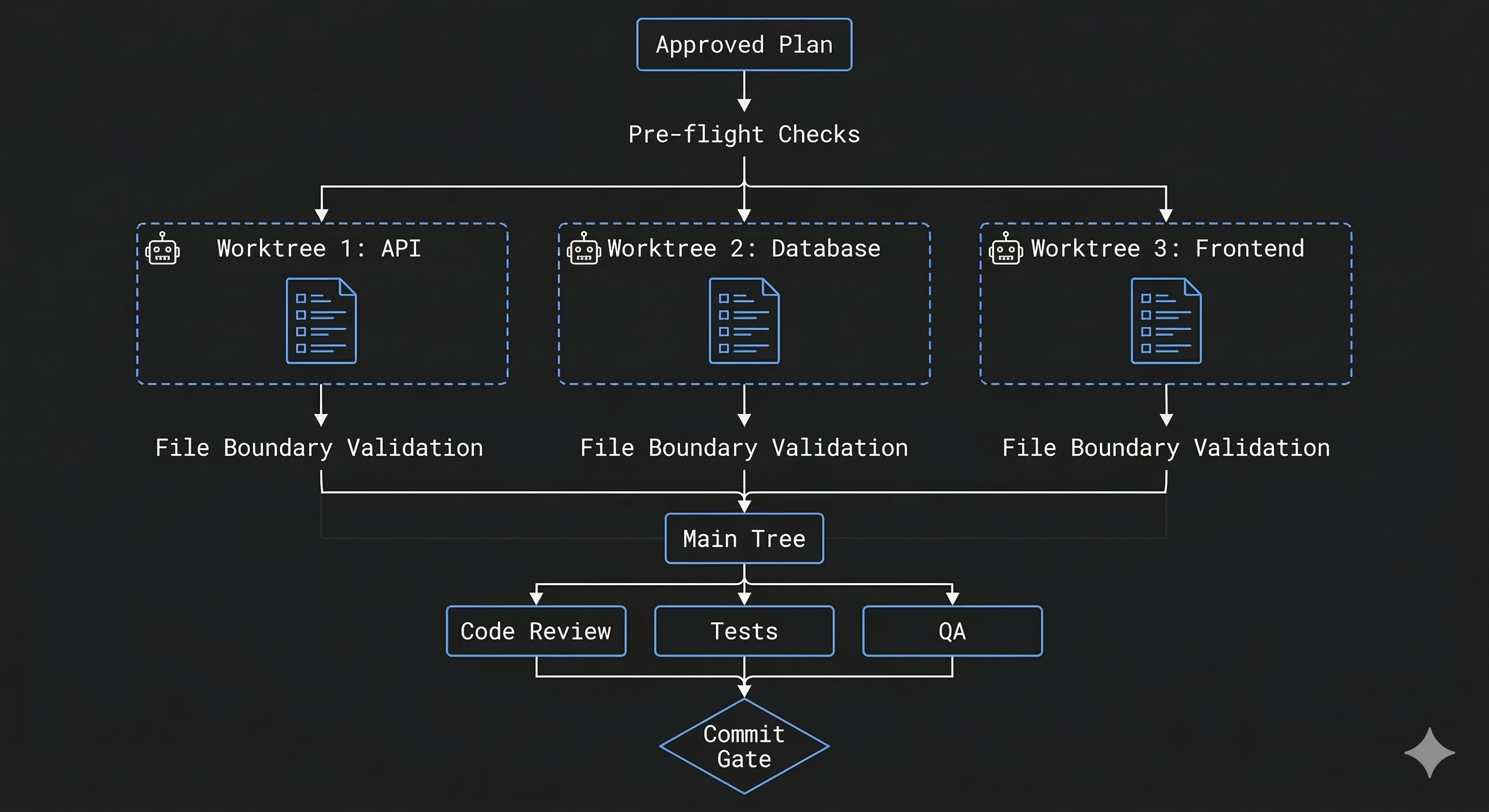
The full pipeline:
- Pre-flight checks (clean working directory, required agents exist)
- Read and validate the plan (requires APPROVED status)
- Pattern validation against
CLAUDE.mdconventions (warnings only) - Worktree creation and parallel coder dispatch
- File boundary validation
- Merge to main tree
- Code review + test execution + QA validation (parallel)
- Revision loop (max 2 iterations)
- Commit gate
/audit: the scanner
/audit runs security and performance scans in parallel, synthesizes results with severity ratings, and produces a verdict: PASS, PASS_WITH_NOTES, or BLOCKED. It auto-detects scope (plan-only, code-only, or full codebase) and archives all reports with ISO timestamps.
/sync: the librarian
/sync detects recent code changes, finds undocumented environment variables, and dispatches a librarian agent to review documentation freshness. If updates are needed, it applies them and shows you the git diff before you commit.
Three archetypes
Every skill in claude-devkit follows one of three structural patterns:
| Archetype | Characteristics | Example |
|---|---|---|
| Coordinator | Delegates to specialists, parallel reviews, bounded revision loops, verdict gates | /dream |
| Pipeline | Sequential checkpoints, pre-flight checks, implementation then review, commit gate | /ship |
| Scan | Scope detection, parallel analysis, severity synthesis, archive on completion | /audit |
These are not suggestions. They’re enforced by the validator. Every skill must have numbered steps (## Step N), tool declarations per step, verdict gates, bounded iterations (no infinite loops), timestamped artifacts, and archive references. 10 patterns total.
When you generate a new skill, you pick an archetype:
gen-skill deploy-check \
--description "Verify deployment health" \
--archetype pipeline \
--deployThe generator produces a valid scaffold. The validator confirms it passes. deploy.sh copies it to ~/.claude/skills/. You customize the TODO placeholders and you have a working skill.
Skills are code. Test them.
Skills are markdown, but they control agent behavior. A missing verdict gate means a broken workflow. A missing bounded iteration means a potential infinite loop. A wrong model declaration means the wrong LLM runs the task.
claude-devkit includes:
validate-skill: Checks 10 architectural patterns. YAML frontmatter, numbered steps, tool declarations, verdict gates, timestamped artifacts, bounded iterations, archive references, scope parameters, model selection, and coordinator role. Returns exit code 0 (pass) or 1 (fail). Supports--jsonfor CI integration.validate-agent: Checks agent definitions for inheritance patterns and structural correctness.- 60 tests across skill and agent generators. Coverage includes all production skills, all 3 archetypes, input validation, negative tests, and metadata verification.
validate-skill skills/dream/SKILL.md # Human-readable report
validate-skill skills/ship/SKILL.md --json # JSON for CI
validate-skill skills/audit/SKILL.md --strict # Warnings as errors
This is the part that matters most. AI workflows without validation are just hopes with extra steps. If you cannot programmatically verify that a skill has the right gates, the right iteration bounds, and the right tool declarations, you cannot trust it to run unattended.
The agent layer
Skills dispatch work to agents. Agents are project-specific markdown files in .claude/agents/ that encode your stack, conventions, and domain knowledge.
claude-devkit generates 5 agent types:
| Agent | Purpose |
|---|---|
| coder | Implementation specialist (stack-aware) |
| qa-engineer | Testing and validation |
| code-reviewer | Review against project patterns |
| security-analyst | Threat modeling and security review |
| senior-architect | High-level design and planning |
cd ~/projects/my-app
gen-agents . # Auto-detects stack from package.json/pyproject.tomlThe generator reads your project files, detects your stack (Next.js, FastAPI, React, Astro, Python, TypeScript, or security tooling), and produces agents with stack-specific instructions. Skills like /dream and /ship check for these agents at runtime. If a project-specific coder exists, /ship uses it. If not, it falls back to a generic subagent.
Why open-source it
Three reasons.
1. The pattern is more valuable than the implementation. The coordinator/pipeline/scan archetypes, the 10 validation patterns, worktree isolation for parallel agents: these are transferable ideas.
2. Skills need a community. The archetype system is designed for extension. A deploy-check pipeline skill. A migrate-db coordinator. A dependency-audit scanner. The generator and validator make it possible for anyone to build skills that follow consistent patterns.
3. I learned this by breaking things. Every pattern in claude-devkit exists because I hit a specific failure mode. Unbounded revision loops that burned tokens forever. Parallel agents overwriting each other’s files. Skills that worked once and broke on the next run because they had no validation. If those failure modes are documented and the solutions are coded into templates, other people skip the expensive lessons.
Getting started
git clone https://github.com/backspace-shmackspace/claude-devkit.git
cd claude-devkit
./scripts/install.sh
source ~/.zshrc
./scripts/deploy.shThen in any Claude Code session:
/dream add user authentication
/ship plans/add-user-authentication.md
/audit
/syncThe GETTING_STARTED.md has a 15-minute walkthrough. The CLAUDE.md has the full architectural documentation.
So what
Most teams are using AI agents the way they used to use bash scripts: write something that works once, run it, fix it when it breaks. That’s fine for one-offs. It’s not a development practice.
The teams that get real leverage from agent tooling in 2026 will be the ones that treat agent workflows the same way they treat application code: versioned, validated, tested, and reviewed before they run.